Zookeeper 集群
Zookeeper 集群架构图
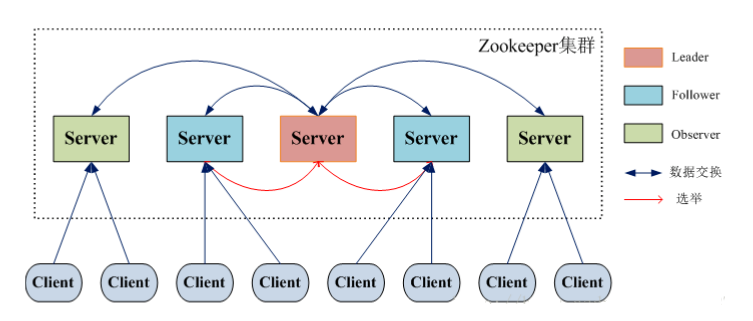
对应的角色

Leader 写操作
ZooKeeper 集群工作的核心 事务请求(写操作) 的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务的调度者。
对于 create,setData,delete 等有写操作的请求,则需要统一转发给 leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
Follower 读操作
处理客户端非事务(读操作)请求,转发事务请求给 Leader; 参与集群 Leader 选举投票(其实就是选 Master)
此外,针对访问量比较大的 zookeeper 集群,还可以新增观察者角色
Observer 读操作
通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力(说白了就是增加并发的请求)
观察者不参与投票,只听取投票结果。除了这个简单的区别,Observers 的功能与 Followers 完全相同
Docker 配置 ZK 集群环境
实在不想安装软件到电脑上,所以这里使用 Docker,为了更方便查看 zookeeper 的运行情况,这里顺道安装了可视化服务 zkui。
编写 docker-compose
配置文件内容:
version: '3'
services:
zoo1:
image: zookeeper
# restart: always
container_name: zoo1
ports:
- '2181:2181'
environment:
ZOO_MY_ID: 1 # 表示zk服务的ID, 取值为1-255之间的整数,且必须唯一
ZOO_SERVERS: ${ZOO_SERVERS}
ZOO_4LW_COMMANDS_WHITELIST: '*' # 命令白名单
volumes:
- ./zoo1/data:/data
- ./zoo1/datalog:/datalog
zoo2:
image: zookeeper
# restart: always
container_name: zoo2
ports:
- '2182:2181'
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: ${ZOO_SERVERS}
ZOO_4LW_COMMANDS_WHITELIST: '*'
volumes:
- ./zoo2/data:/data
- ./zoo2/datalog:/datalog
zoo3:
image: zookeeper
# restart: always
container_name: zoo3
ports:
- '2183:2181'
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: ${ZOO_SERVERS}
ZOO_4LW_COMMANDS_WHITELIST: '*'
volumes:
- ./zoo3/data:/data
- ./zoo3/datalog:/datalog
# zkui:
# image: juris/zkui # 排行第一的那个镜像用不了
# container_name: zkui
# ports:
# - '9090:9090'
# volumes:
# - ./zkui/config.cfg:/var/app/config.cfg
# environment:
# ZK_SERVER: ${ZOOKEEPER_SERVERS}
ZOO_MY_ID:表示zk服务的ID, 取值为1-255之间的整数,且必须唯一 ZOO_SERVERS:表示zk集群的主机列表
编写 .env 文件,这个 ZOO_SERVERS 的配置语法参考 Specifying the client port
ZOO_SERVERS=server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
启动服务
docker-compose up -d
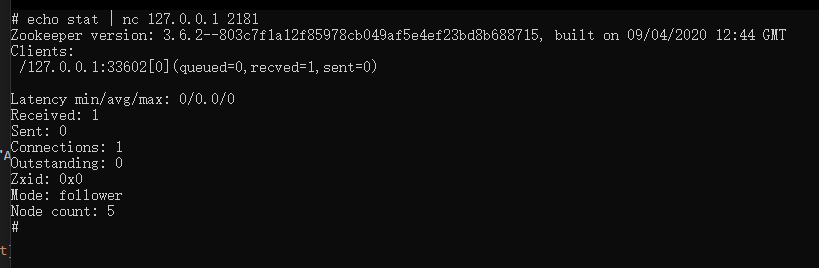
到 Zookeeper 服务里面输入
echo stat | nc 127.0.0.1 2181
检查是否启动成功
进到 bin 目录可以查看使用它内置的脚本
# 启动:
zkServer.sh start
# 停止:
zkServer.sh stop
# 查看状态:
zkServer.sh status
原子广播
使用上面搭建的集群可以发现不管在哪个实例上操作 ZK,其它的两台服务也能同步更新,ZK 就是通过一个叫做 zab的协议来做到的
zab协议 的全称是 Zookeeper Atomic Broadcast (zookeeper原子广播),zookeeper 是通过 zab协议来保证分布式事务的最终一致性。
基于 zab协议,zookeeper 集群中的角色主要有以下三类,如下表所示:

可以通过 ./zkServer.sh status 命令查看当前服务的状态

zab广播模式工作原理,通过类似两阶段提交协议的方式解决数据一致性:

- leader 从客户端收到一个写请求
- leader 生成一个新的事务并为这个事务生成一个唯一的 ZXID
- leader 将这个事务提议(propose)发送给所有的 follows 节点
- follower 节点将收到的事务请求加入到历史队列(history queue)中,并发送 ack 给 leader
- 当 leader 收到大多数 follower(半数以上节点)的 ack 消息,leader 会发送 commit 请求
- 当 follower 收到 commit 请求时,从历史队列中将事务请求 commit
Leader 选举 🙅
这一部分待完善...
等工作一段时间后再来补充
服务器状态
- looking:寻找 leader 状态。当服务器处于该状态时,它会认为当前集群中没有 leader,因此需要进入 leader 选举状态。
- leading: 领导者状态。表明当前服务器角色是 leader。
- following: 跟随者状态。表明当前服务器角色是 follower。
- observing:观察者状态。表明当前服务器角色是 observer。
服务器启动期的 leader 选举
在集群初始化阶段,当有一台服务器 server1 启动时,其单独无法进行和完成 leader 选举,当第二台服务器 server2 启动时,此时两台机器可以相互通信,每台机器都试图找到 leader,于是进入 leader 选举过程。选举过程如下:
1、每个 server 发出一个投票。由于是初始情况,server1 和 server2 都会将自己作为 leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 zxid,使用 (myid, zxid) 来表示,此时 server1 的投票为 (1, 0),server2 的投票为 (2, 0),然后各自将这个投票发给集群中其他机器。
2、集群中的每台服务器接收来自集群中各个服务器的投票。
3、处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行pk,pk规则如下:
- 优先检查 zxid,zxid 比较大的服务器优先作为 leader。
- 如果 zxid 相同,那么就比较 myid。myid 较大的服务器作为 leader 服务器。
- 对于 Server1 而言,它的投票是
(1, 0),接收 Server2 的投票为(2, 0),首先会比较两者的 zxid,均为 0,再比较 myid,此时 Server2 的 myid 最大,于是更新自己的投票为(2, 0),然后重新投票,对于server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
4、统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 Server1、Server2 而言,都统计出集群中已经有两台机器接受了 (2, 0) 的投票信息,此时便认为已经选出了 leader。
5、改变服务器状态。一旦确定了 leader,每个服务器就会更新自己的状态,如果是 follower,那么就变更为 following,如果是 leader,就变更为 leading。
服务器运行期的 leader 选举
在 zookeeper 运行期间,leader 与非leader 服务器各司其职,即便当有非leader 服务器宕机或新加入,此时也不会影响leader,但是一旦 leader 服务器挂了,那么整个集群将暂停对外服务,进入新一轮 leader 选举,其过程和启动时期的 Leader 选举过程基本一致。
假设正在运行的有 server1、server2、server3 三台服务器,当前 leader 是 server2,若某一时刻 leader 挂了,此时便开始 Leader 选举。选举过程如下:
1、变更状态。leader 挂后,余下的服务器都会将自己的服务器状态变更为 looking,然后开始进入 leader 选举过程。
2、每个server会发出一个投票。在运行期间,每个服务器上的 zxid 可能不同,此时假定 server1 的 zxid 为 122,server3 的 zxid 为 122,在第一轮投票中,server1 和 server3 都会投自己,产生投票 (1, 122),(3, 122),然后各自将投票发送给集群中所有机器。
3、接收来自各个服务器的投票。与启动时过程相同
4、处理投票。与启动时过程相同,此时,server3 将会成为leader。
5、统计投票。与启动时过程相同。
6、改变服务器的状态。与启动时过程相同。
observer 角色及其配置
observer角色特点:
- 不参与集群的 leader 选举
- 不参与集群中写数据时的 ack 反馈
配置步骤:
1、为了使用 observer 角色,在想变成 observer 角色的配置文件中加入如下配置:
peerType=observer
2、并在所有 server 的配置文件中,配置成 observer 模式的 server 的那行配置追加 :observer 如下所示
server.3=172.26.183.187:2289:3389:observer
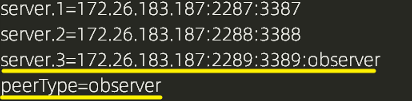
Zookeeper 集群的配置
zookeeper 集群模式配置文件
#间隔都是使用tickTime的倍数来表示的,例如initLimit=10就是tickTime的十倍等于2W毫秒
tickTime=2000
# 集群中的 follower 服务器与 leader 服务器之间请求和应答之间能容忍的最多心跳数(tickTime 的数量)。
syncLimit=5
# Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
dataDir=/home/michael/opt/zookeeper/data
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
# the maximum number of client connections. increase this if you need to handle more clients
# 允许连接的客户端数目,0-不限制,通过 IP 来区分不同的客户端
maxClientCnxns=60
#将管理机器把事务日志写入到“ dataLogDir ”所指定的目录,而不是“ dataDir ”所指定的目录。避免日志和快照之间的竞争
#dataLogDir=/root/Hadoop-0.20.2/zookeeper-3.3.1/log/data_log
# The number of snapshots to retain in dataDir
#用于配置zookeeper在自动清理的时候需要保留的快照数据文件数量和对应的事务日志文件,最小值时三,如果比3小,会自动调整为3
#autopurge.snapRetainCount=3
# Purge task interval in hours. Set to "0" to disable auto purge feature
#配套snapRetainCount使用,用于配置zk进行历史文件自动清理的频率,如果参数配置为0或者小于零,就表示不开启定时清理功能,默认不开启
#autopurge.purgeInterval=1
##集群配置
# The number of ticks that the initial, synchronization phase can take
# follow服务器在启动的过程中会与leader服务器建立链接并完成对数据的同步,leader服务器允许follow在initLimit时间内完成,默认时10.集群量增大时
#同步时间变长,有必要适当的调大这个参数, 当超过设置倍数的 tickTime 时间,则连接失败
initLimit=10
# server.A=B:C:D:其中 A 数字,表示是第几号服务器. dataDir目录下必有一个myid文件,里面只存储A的值,ZK启动时读取此文件,与下面列表比较判断是哪个server
# B 是服务器 ip ;C表示与 Leader 服务器交换信息的端口;D 表示的是进行选举时的通信端口。
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
# 配置成observer模式
peerType=observer
# 注意观察者角色的末尾,需要拼接上observer
server.4=10.2.143.38:2886:3886:observer
如果使用的是 Docker 搭建的环境,则参考这里的配置 zookeeper
Reference
参考资料 zookeeper 官方镜像 参考资料 zkui 的镜像